I measured the total time required to fork a new process, have it exit immediately, and have its parent reap it. This was measured with respect to three different pid allocation algorithms, and with varying numbers of other sleeping processes occupying pids. The goal of the test was to determine which of the pid allocators performed the best in a variety of circumstances.
The contending pid allocation algorithms were:
retry:
foreach process p in the system {
if (nextpid == p.pid) {
nextpid++;
goto retry;
}
}
Although there is an added heuristic that depends on the order of the
allproc list, this operation can be O(mn), where
m is the number of processes in the system and n is the
number of pids that must be searched.
The test environment consisted of a 450 MHz Pentium 3 with 384 MB of RAM running FreeBSD-CURRENT-20040206 with the usual debugging options disabled. The test program forks the specified number of "sleeper" processes with random pids, then measures the time required to fork a child and wait for that child to exit immediately. (The fork()/wait4() operation is iterated many times to increase the accuracy of the results.)
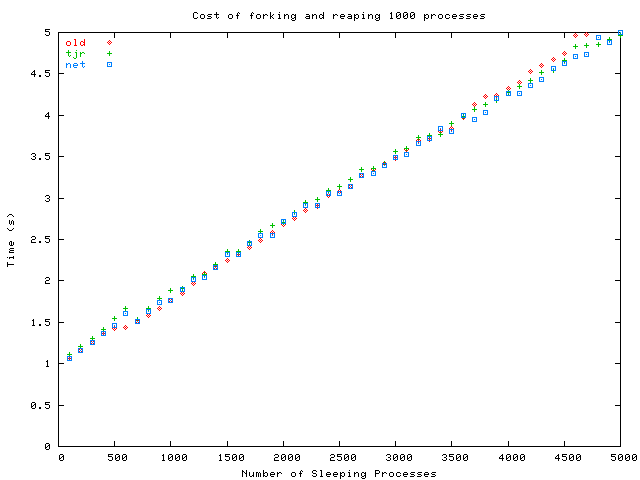
The results of running the test for 1000 forks with the three algorithms (repeated 3 times each) are presented in the figure above. The "better" algorithms performed nearly as badly as the old allocator, so clearly confounding factors were involved. Through profiling, I identified two performance bottlenecks:
To correct for these, I made two changes to the test program:
Fork time decreased so much that I had to run 10,000 iterations instead of 1000 in order to avoid excessive jitter. The results for the new test program are below.
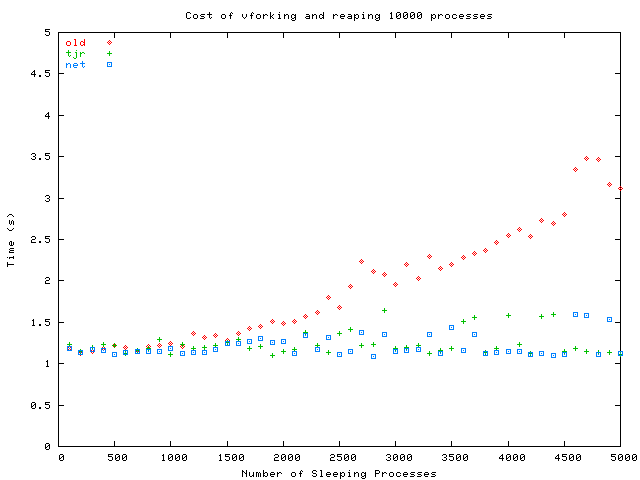
These results demonstrate that both of the new approaches are effective and solve a real performance problem for systems with many processes. Moreover, there is no statistically significant performance impact in the common case of only several hundred processes. So is Tim's approach or the NetBSD approach more appropriate? I'm inclined to opt for Tim's allocator because:
Another interesting observation is that the variance is much higher when there are more sleeping processes. What accounts for these random spikes? The measurements were taken with the ULE scheduler, so there's no schedcpu(). One theory is that the additional memory pressure caused the pageout daemon to kick into gear at unpredictable times to look for clean pages to evict. (The test system was not configured with swap.) In any case, it's possible that some other component of the system behaves badly when there are many processes.