Seeing as how some folks have expressed their concerns regarding the performance of mb_alloc when compared to the present mbuf and cluster allocator, I decided (okay, maybe I was convinced :-)) to put up this page and try to produce some measurements.
Before looking at the results, please understand that mb_alloc was designed with two main intentions:
Since -CURRENT is presently in a state where Giant still reigns over the kernel, the true effects of reduced contention and real cache use improvements will only be noted as Giant is unwound. However, if one can presently observe, even with Giant in place, reasonably comparable performance results, then it is a guarantee that when Giant is unwound, the performance can only get better. The latter observations will hopefully be made from the results displayed here.
As for the second point (regarding the reclamation of resources), the results are frankly self-evident. I have not yet implemented lazy freeing from a kproc but have taken it into consideration during the design of mb_alloc, so that implementing the feature in the near future should be relatively painless. The major benefit of the feature will be that the system will still perform as usual but, if network activity greatly peaks only then to return below some configurable watermark, the system would reclaim the unused (and therefore wasted) wired-down pages and, consequently, reduce the occurance of heavy swapping.
In an effort to reduce as most as possible the irregularities caused by the need to allocate pages during NetPIPE performance testing, I have configured both the present allocator code as well as mb_alloc to allocate sufficient mbufs and clusters during bootup. By "sufficient" I simply mean "as much as the largest/toughest NetPIPE test will require." This of course eliminated the need for both sets of code to perform [expensive] map allocations and produce irregularities in the results.
The present allocator code is a fresh cvsup of -CURRENT from the end of June 14th. The mb_alloc code is the latest mb_alloc patch applied to the same (cvsup-ed) tree with one important modification. The "latest version" of the released mb_alloc code, due to simplicity purposes, forces all cluster allocations to be accompanied with relatively expensive (in light of performance testing) malloc() calls. The malloc() calls serve to allocate 4-byte space for reference counters. To make things worse, the freeing of clusters is also always accompanied by a call to free(). When I posted the latest mb_alloc code to the FreeBSD mailing lists requesting testing, I pointed this fact out and mentionned that it was a temporary change that would soon be replaced; the intention is to use the end of the cluster itself as space for the reference counter (since this is unused space, anyway). In order to obtain more realistic measurements, I quickly hacked this into my local version of mb_alloc and was on my way.
The following graphs were produced from results obtained with NetPIPE (Network Protocol Independent Performance Evaluator). It's, in my opinion, a fairly nice network performance evaluation tool and it just so happens that it's not yet a FreeBSD port (*hint* *hint*). These tests were all performed with the TCP performance evaluation tool which happens to be the standard produced by the NetPIPE build (the binary is named `NPtcp').
The first test was a local test (the sending and receiving binaries were executed on the same machine). This allowed for the maximum throughput to not be capped by the throughput limitations of ethernet. Two types of tests were performed. The first is a "block send" test, which is in effect a ping-pong type test; the sending client sends a block of data, waits for it to be acknowledged, and only then goes on to send the next block of data. The second test is a "stream send" test, which consists of the sender continuously sending data without waiting for acknowledgment from the receiving end, and thus is significantly tougher on the allocation code. Both test descriptions and example analysis is provided in the NetPIPE paper.
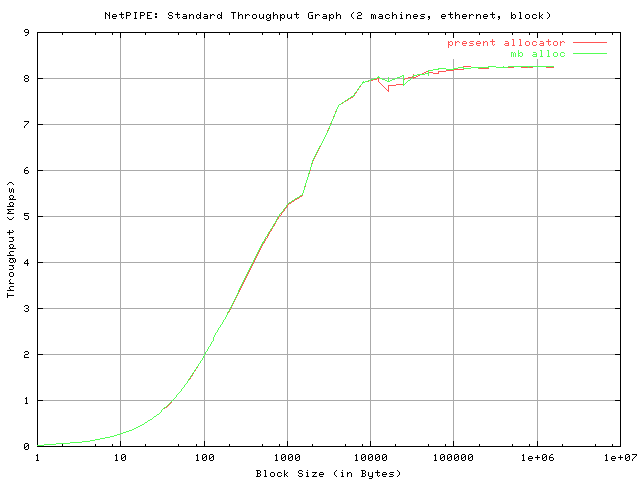
The first graph entitled "NetPIPE: Standard Throughput Graph" is a plot of the throughput versus the used block size. For better illustration of small block sizes, the block size axis is scaled logarithmically.
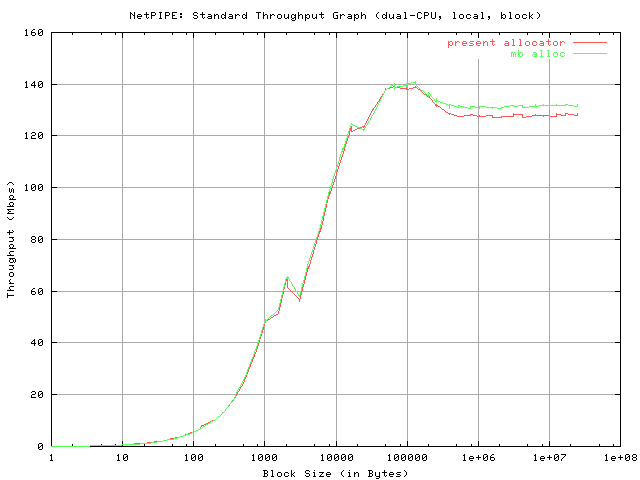
Clearly, with Giant still in place, both allocators on the dual-processor system are very comparable. The difference being that the maximum throughput (peak) is slightly higher in the mb_alloc case and that for higher block sizes, the mb_alloc code consistently shows slightly higher throughput. This trend can also be observed in the "stream send" tests (see below).
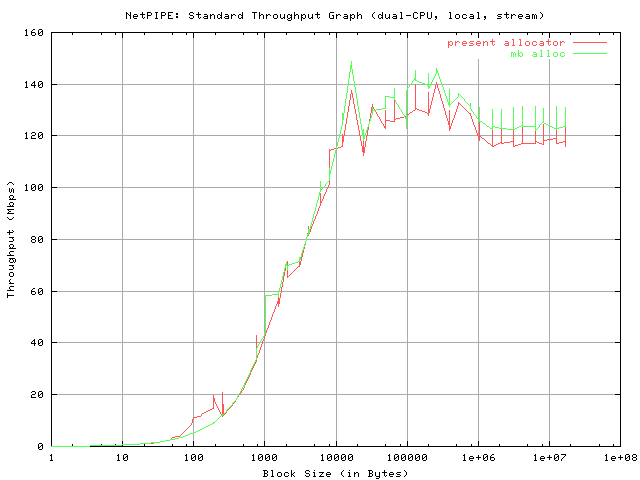
The explanation for the maintenance of consistently higher throughput as the block size increases for mb_alloc may be attributed to overall better cache utilization. This is nonetheless a small (if at all arguable) improvement, and I suspect a greater improvement when Giant is unwound (primarily due to minimized lock contention).
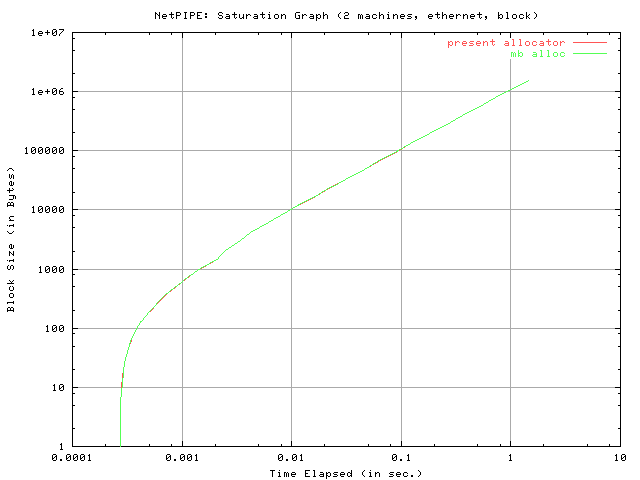
The next graph is entitled "NetPIPE: Saturation Graph" and is a plot of the block size versus the elapsed time. It should be noted that both axes are logarithmically scaled. The purpose of the Saturation Graph is to primarily identify the so-called saturation point, that is the point at which the slope of the graph becomes approximately constant.
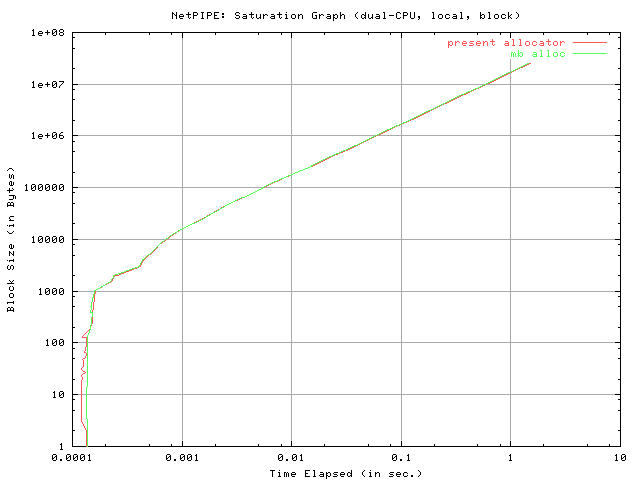
The results of the "block send" tests seem to indicate that the saturation point for both sets of code is approximately the same. It also appears that the present allocator is slightly faster for small block sizes (under 100 bytes). However, remember that because the "elapsed time" values vary logarithmically the actual difference in times for the small block sizes is not very large, and arguably insignificant. The results of the "stream send" test reveal the same trend (see below).
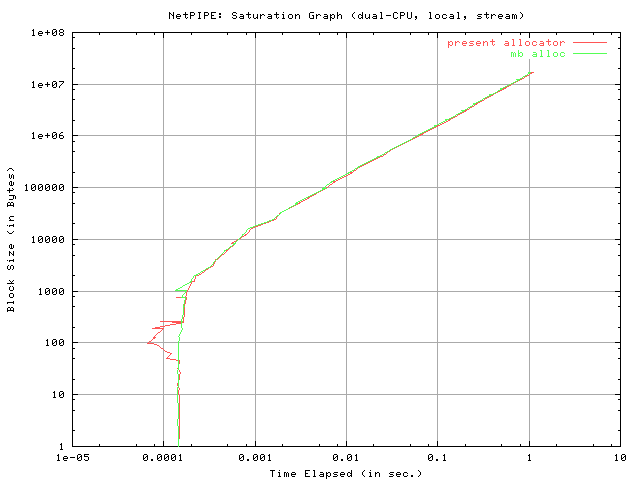
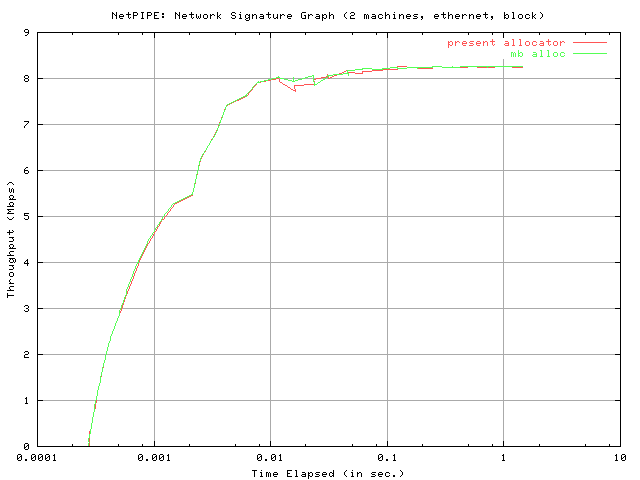
The final graphs in this data set, entitled "NetPIPE: Network Signature Graph," are effectively a representation of network acceleration. It is a plot of the throughput versus the time elapsed. It should be noted that the time elapsed axis is logarithmically scaled.
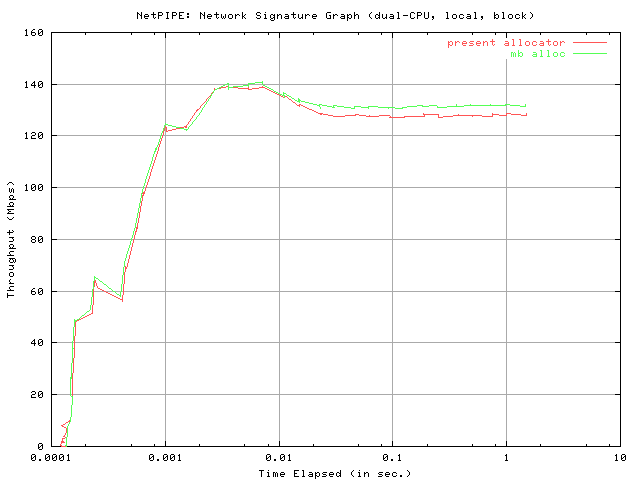
Clearly, both graphs are extremely comparable. The present allocator seems to have a very slightly smaller latency time, as conveniently represented by the time at which the graph emerges in the grid (remember, though, that the elapsed time varies logarithmically, so this is a small difference). The mb_alloc allocator seems to imply, once again, a slightly higher maximum throughput and the consistently [slightly] higher throughput appears to be maintained as time elapses (therefore, for larger block sizes). The same trend can be observed from the "stream send" results below.
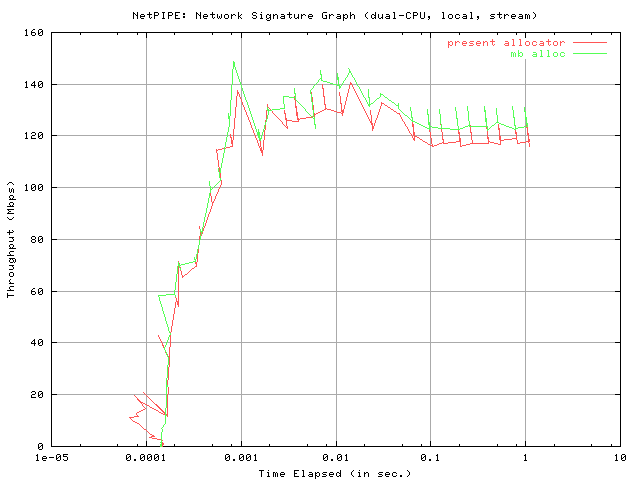
Clearly, both allocators appear to show similar accelerations toward peak throughput.
The results below were obtained following testing done over ethernet. The first machine ran the `NPtcp' (NetPIPE) send client and the second machine ran the receive client. The first machine is an Intel dual Pentium II (300 MHz) while the second machine is an Intel dual PPro 180. The first machine sports a PCI 3Com 3C595 while the second sports a cheap old PCI RealTek 8029. As of date, only the "block send" test was performed. I'll look into running the "stream send" tests and posting the results soon.
The "block send" test reveals that mb_alloc stays very close to the present allocator in terms of performance and is even found slightly surpassing throughput for a small subset of tested block sizes. Both curves peak at a roughly equivalent maximum throughput, which is likely due to the limitations of ethernet. Similarly, both data sets indicate an approximately identical latency time (see "Network Signature" graph). The "Saturation Graph" reveals that both allocators produce an identical saturation point.
Jonathan Lemon was kind enough to produce some results on his 6-way PPro. Take a look here.
I'm working on producing other graphs with results.
Hopefully, the results above illustrate that even in the presence of Giant, when the main theoretical performance advantages of mb_alloc are not expected, the performance of the latter is very comparable to the present allocator. The mb_alloc allocator implements the infrastructure required for proper resource reclamation (something both OpenBSD and NetBSD have had for a while) while remaining, even with Giant in place, comparable to the present allocator and while allowing for better scalability in the future, when Giant will be unwound.